本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/302641.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

SpringCloud-高级篇(十一)
(1)搭建Redis-主从架构
前面我们实现了Redis的持久化,解决了数据安全问题,但是还有需要解决的问题,下面学习Redis的主从集群,解决Redis的并发能力的问题 Redis的集群往往是主从集群,Redsi为什么…



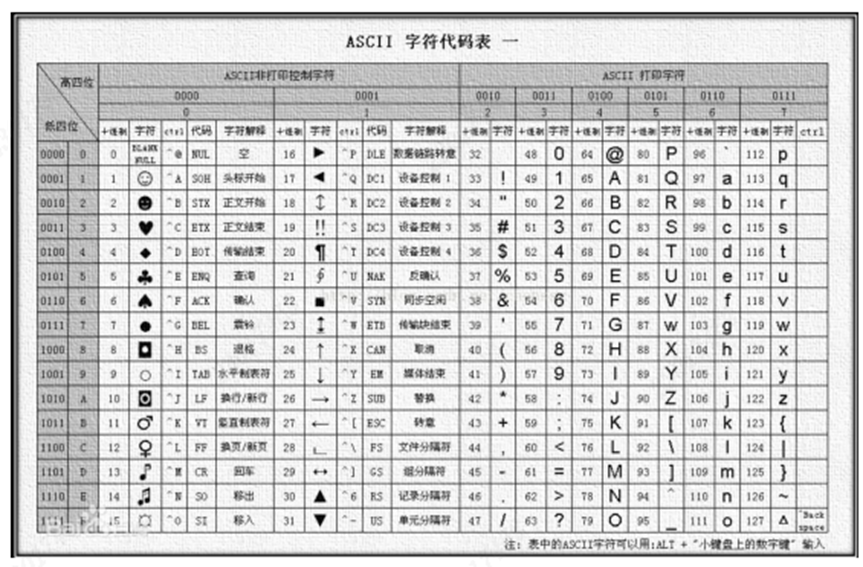
【HBase】——优化
1 RowKey设计
重要:一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于 哪个一个预分区的区间内,设计 rowkey的主要目的 ,就是让数据均匀的分布于所有的 region 中,在一定程度…
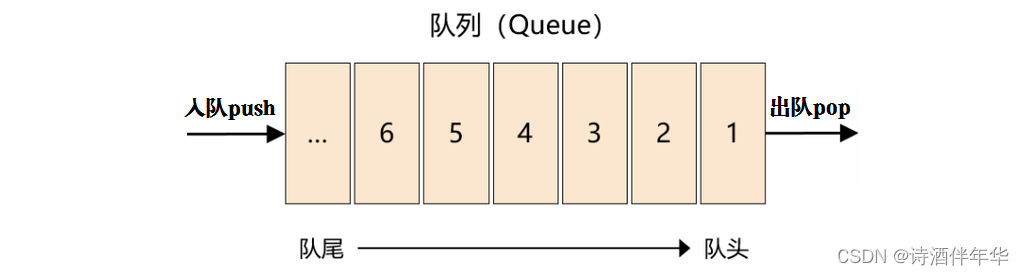
C++——STL标准模板库——容器详解——stack+queue
一、基本概念
(一)stack(栈或堆栈)
一种只允许同一端进出的线性数据结构,数据先进后出。基本模型类似于瓶子。
(二)queue(队列)
一种只允许一端进、另一端出的线性数…

HTML中的主根元素、文档元数据、分区根元素、内容分区、文本内容 和 内联文本语义
本文主要介绍了HTML中主根元素<html>、文档元数据<base>、<head>、<link>、<meta>、<style>、<title>、分区根元素<body>、内容分区<address>、<article>、<aside>、<footer>、<h1> (en-US), &…
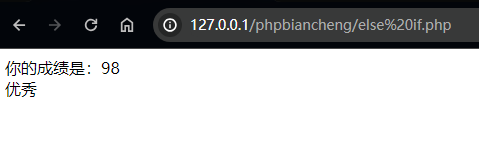
PHP 基础编程 1
文章目录 前后端交互尝试php简介php版本php 基础语法php的变量前后端交互 - 计算器体验php数据类型php的常量和变量的区别php的运算符算数运算符自增自减比较运算符赋值运算符逻辑运算 php的控制结构ifelseelse if 前后端交互尝试 前端编程语言:JS (Java…

ArkTS - 网络请求
一、Axios请求
应用通过HTTP发起一个数据请求,支持常见的GET、POST、OPTIONS、HEAD、PUT、DELETE、TRACE、CONNECT方法。
前端开发肯定都使用过一个叫axios的第三方库,它是是一个基于 promise 的网络请求库,可以用于浏览器和 node.js&…

【UnityShader入门精要学习笔记】(2)GPU流水线
本系列为作者学习UnityShader入门精要而作的笔记,内容将包括:
书本中句子照抄 个人批注项目源码一堆新手会犯的错误潜在的太监断更,有始无终
总之适用于同样开始学习Shader的同学们进行有取舍的参考。 文章目录 上节复习GPU流水线顶点着色…
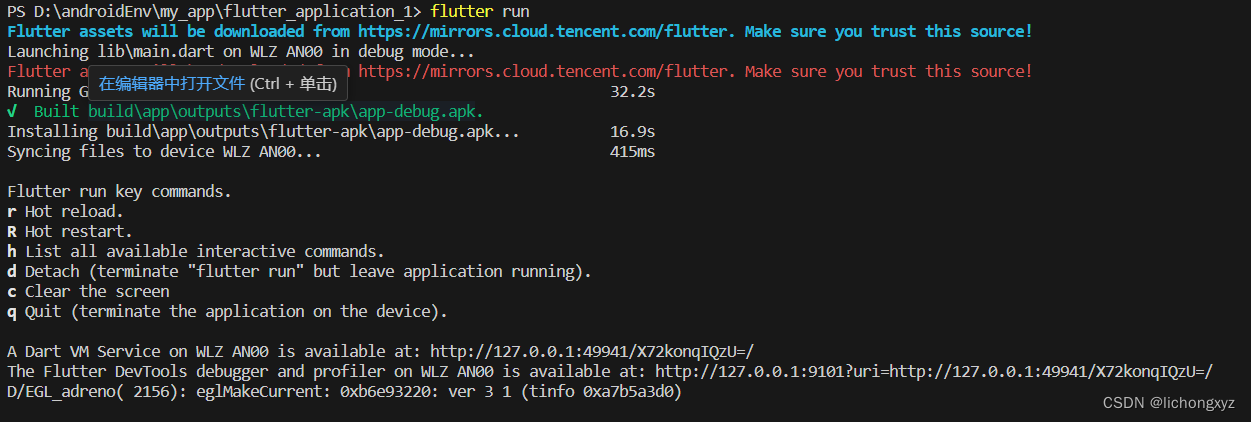
flutter版本升级后,解决真机和模拟器运行错误问题
flutter从3.3.2升级到3.16.0,项目运行到真机和模拟器报同样的错,错误如下: 解决办法:在android目录下的build.gradle加入下面这行,如下图: 重新运行,正常把apk安装到真机上或者运行到模拟器上
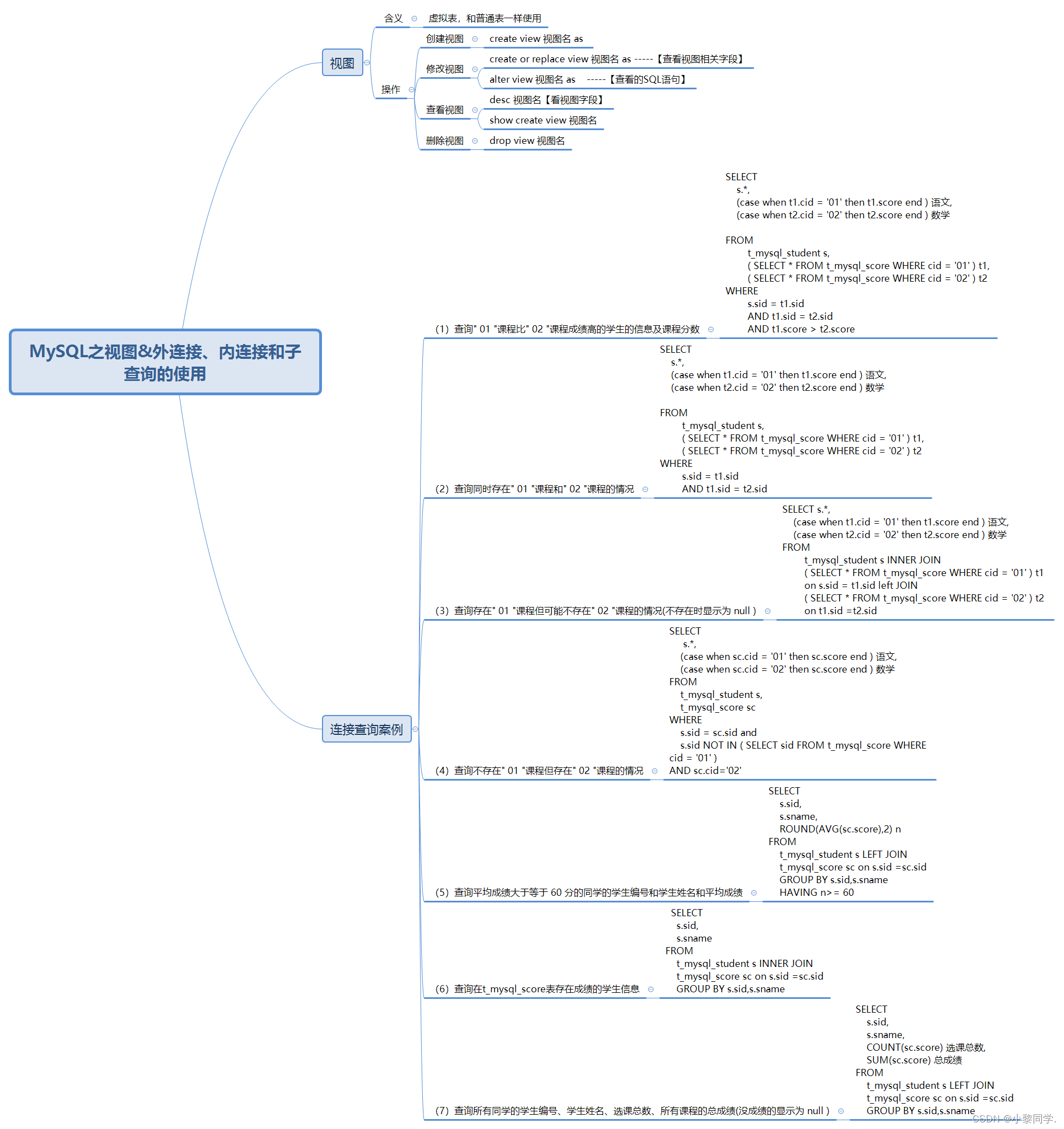
MySQL之视图外连接、内连接和子查询的使用
一、视图
1.1 含义 虚拟表,和普通表一样使用 1.2 操作
创建视图 create view 视图名 as 修改视图 方式一: create or replace view 视图名 as 【查看视图相关字段】 方式二: alter view 视图名 as 【查看的SQL语句】 查看视图 方式一&…
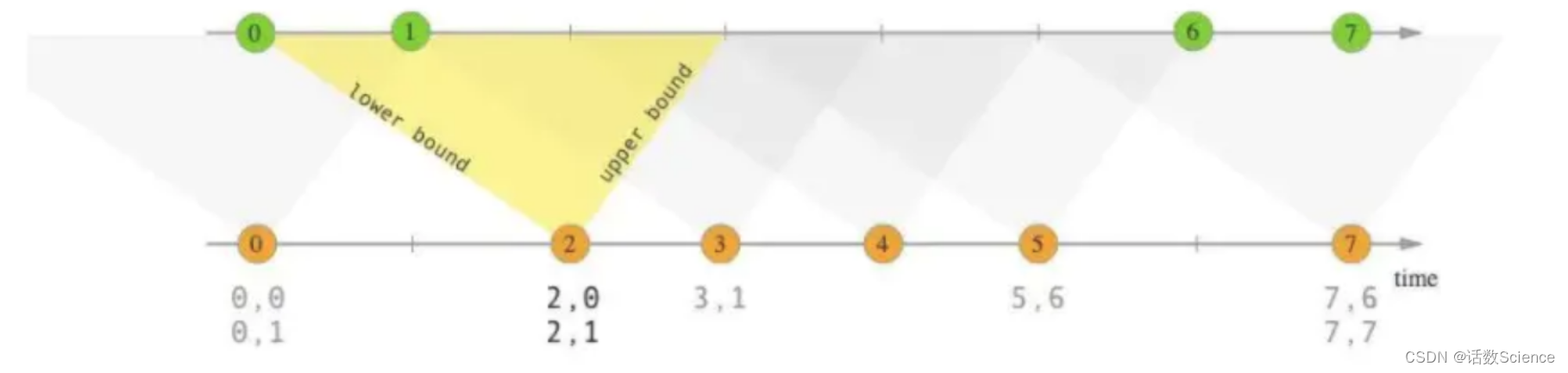
【Flink精讲】Flink数据延迟处理
面试题:Flink数据延迟怎么处理?
将迟到数据直接丢弃【默认方案】将迟到数据收集起来另外处理(旁路输出)重新激活已经关闭的窗口并重新计算以修正结果(Lateness)
Flink数据延迟处理方案
用一个案例说明三…

vivado xsim 终端 模拟
只模拟的话直接终端运行会快很多 计数器举例
mkdir srccounter.v
module counter(input wire clk,input wire rst_n,output reg[31:0] cnt
);
always (posedge clk or negedge rst_n)if(!rst_n)cnt < 31h0;elsecnt < cnt1;endmodule tb.v
module tb;
wire[31:0] out…
华为商城秒杀时加密验证 device_data 的算法研究
前言
之前华为商城放出 Mate60 手机时, 想给自己和家人抢购一两台,手动刷了好几天无果后,决定尝试编写程序,直接发送 POST 请求来抢。通过抓包和简单重放发送后,始终不成功。仔细研究,发现 Cookie 中有一个名为 devic…
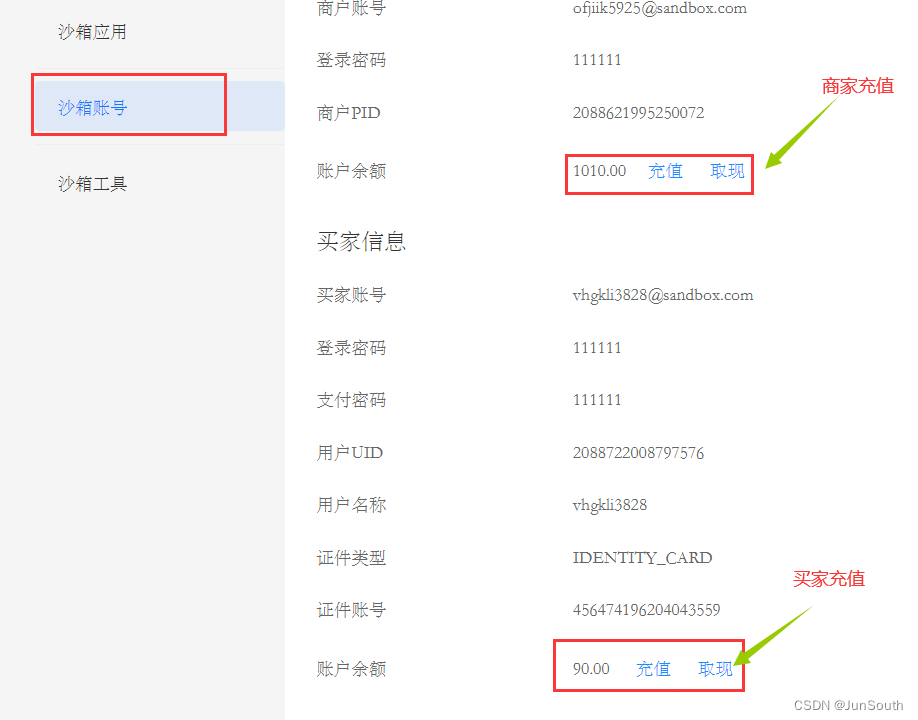
SpringBoot—支付—支付宝
一、流程 二、沙箱操作 1.用支付宝账号登录【开放控制平台】创建应用获取 appid 2.选择沙箱模拟环境 3.沙箱应用-》获取appid(一个appid绑定一个收款支付宝账户) 4.利用开发助手工具生成RSA2密钥 公钥:传给支付宝平台 私钥:配置代码中,…
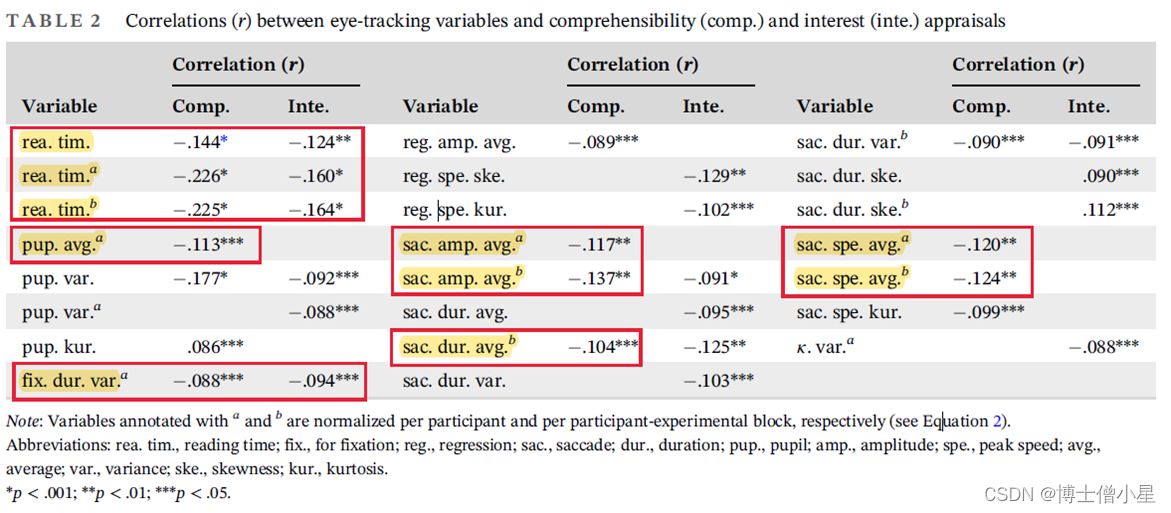
科研学习|论文解读——超准确性反馈:使用眼动追踪来检测阅读过程中的可理解性和兴趣
摘要: 了解用户想要什么信息是信息科学和技术面临的最大挑战。隐式反馈是解决这一挑战的关键,因为它允许信息系统了解用户的需求和偏好。然而,可用的反馈往往是有限的,而且其解释也很困难。为了应对这一挑战,我们提出了…
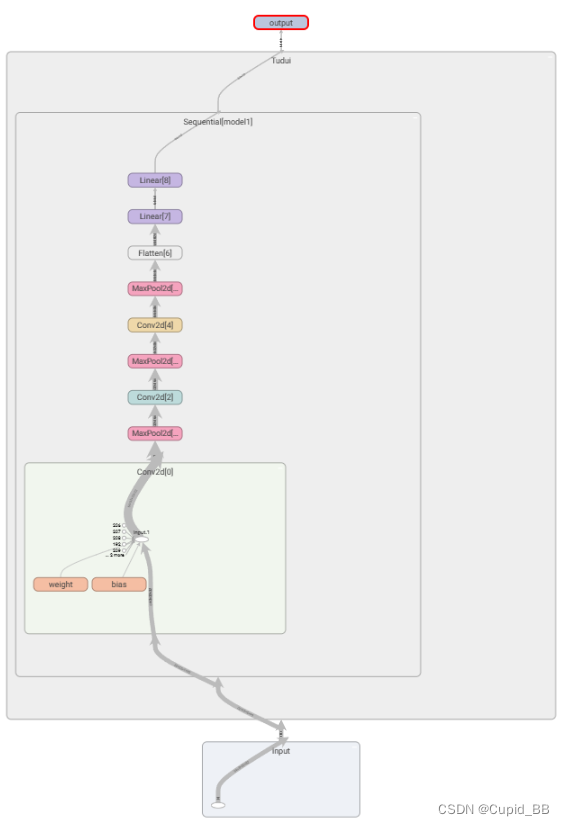
神经网络-搭建小实战和Sequential的使用
CIFAR-10 model structure 通过已知参数(高、宽、dilation1、kernel_size)推断stride和padding的大小 网络
import torch
from torch import nnclass Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.conv1 nn.Conv2d(in_chan…

【shell漫步】3 条件分支结构
碎碎念
接上文的运算符的内容,这一章终于开始接触控制结构
【shell漫步】2 运算符-CSDN博客
分支结构的写法
当我们要对不同情况采取不同措施的时候就要用到分支结构
在shell中分支结构的写法如下
if [ 情况1 ]
then代码1
elif [ 情况2 ]
then代码2
elif [ 情…
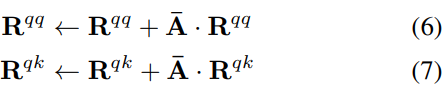
Transformer-MM-Explainability
two modalities are separated by the [SEP] token,the numbers in each attention module represent the Eq. number. E h _h h is the mean, ∇ \nabla ∇A : ∂ y t ∂ A {∂y_t}\over∂A ∂A∂ytfor y t y_t yt which is the model’s out…