本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.ldbm.cn/p/462167.html
如若内容造成侵权/违法违规/事实不符,请联系编程新知网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
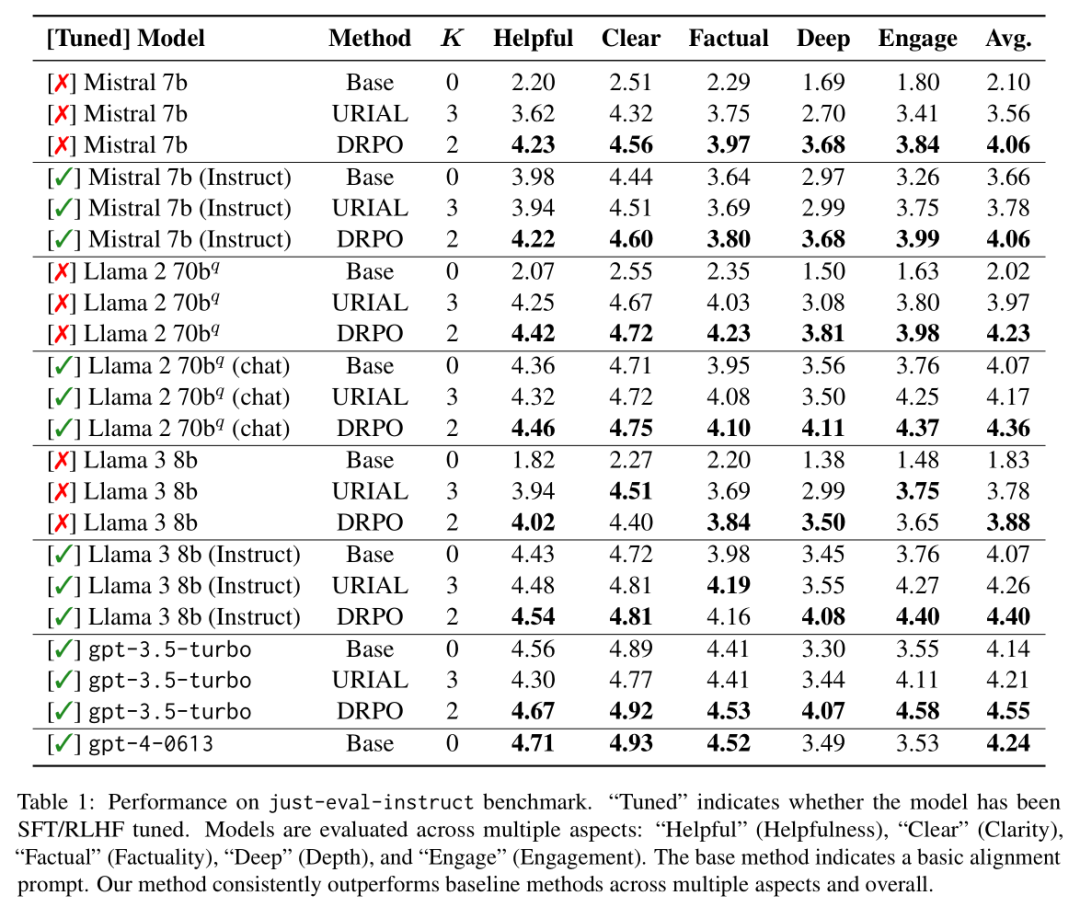
NLP论文速读(EMNLP 2024)|动态奖励与提示优化来帮助语言模型的进行自我对齐
论文速读|Dynamic Rewarding with Prompt Optimization Enables Tuning-free Self-Alignment of Language Models 论文信息: 简介: 本文讨论的背景是大型语言模型(LLMs)的自我对齐问题。传统的LLMs对齐方法依赖于昂贵的训练和人类偏好注释&am…

【会话文本nlp】对话文本解析库pyconverse使用教程版本报错、模型下载等问题解决超参数调试
前言: 此篇博客用于记录调用pyconverse库解析对话文本时遇到的问题与解决思路,以供大家参考。 文章目录 pycoverse介绍代码github链接问题解决1 [cannot import name ‘cached_download‘ from ‘huggingface_hub‘ 问题解决](https://blog.csdn.net/wei…

程序里sendStringParametersAsUnicode=true的配置导致sql server cpu使用率高问题处理
一 问题描述
近期生产环境几台sql server从库cpu使用率总是打满,发现抓的带变量值的慢sql,手动代入变量值执行并不慢,秒级返回,不知道问题出在哪里。
二 问题排查
用扩展事件或者sql profiler抓慢sql,抓到了变量值&…

<项目代码>YOLOv8 瞳孔识别<目标检测>
YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN),YOLOv8具有更高的…

大模型投喂私有化的数据
1.部署大模型 https://blog.csdn.net/YXWik/article/details/143871588 下载安装软件:anythingllm 下载地址:https://anythingllm.com/desktop 一般通用大模型无法满足企业实际业务需求,涉及到知识局限性、信息安全等问题,企业不…


sqlmap图形化安装使用(附文件)
1.需要python环境,我这里就不教如何安装python环境了。
2.下载压缩包并且解压 3. 凭自己喜好选择大窗口小窗口 4.进入图形化界面后,1.输入url地址。2.选择要执行的操作。3.构造命令语句 5.点击一把梭,然后就可以发现出结果了 6. 对于喜欢自己…

go-zero(六) JWT鉴权
go-zero JWT鉴权
还记得我们之前登录功能,返回的信息是token吗? 这个token其实就是JSON Web Token简称JWT,它是一种开放标准(RFC 7519),用于在网络应用环境间安全地传递声明信息。
它是一种基于 JSON 的令牌…

单片机学习笔记 5. 数码管静态显示
更多单片机学习笔记:单片机学习笔记 1. 点亮一个LED灯单片机学习笔记 2. LED灯闪烁单片机学习笔记 3. LED灯流水灯单片机学习笔记 4. 蜂鸣器滴~滴~滴~ 目录
0、实现的功能
1、Keil工程
1-1 数码管显示原理
1-2 静态与动态显示
1-3 74HC573锁存器的工作原理
1-…

商业iOS端路由架构演进
背景
目前商业SDK中的点击事件,会根据不同的「事件类型」「业务类型」,去执行不同的路由跳转逻辑,然而不同的跳转事件内部又有着很复杂的跳转逻辑,
痛点
不同的跳转逻辑之间存在耦合 例如,在deeplink的跳转逻辑之中…

如何管理服务中的 “昂贵” 资源
如果接触过实际大型业务系统,就能体会到许多业务的正常运行都依赖于各种昂贵的第三方接口,调用一次都是要花元子的,例如
大语言模型nlp 服务:信息提取、分类等cv 服务:定位、信息提取、分类等
然而经常可能由于各种无…

Matlab深度学习(四)——AlexNet卷积神经网络
网络搭建参考:手撕 CNN 经典网络之 AlexNet(理论篇)-CSDN博客 在实际工程应用中,构建并训练一个大规模的卷积神经网络是比较复杂的,需要大量的数据以及高性能的硬件。如果通过训练好的典型网络稍加改进…

高效语言模型 Parler-TTS 上线,一键完成文本转语音
Parler-TTS 是一种轻量级的文本转语音 (TTS) 模型,可以生成具有给定说话者风格的高质量、自然语音,自由度及创新性非常高,并且可以通过 Prompt 控制说话者的性别、音色、语调以及所处的场景(室内、室外、马路上、音乐厅等…

了解鱼叉式网络钓鱼攻击的社会工程学元素
一提到网络攻击,你可能会想象一个老练的黑客躲在类似《黑客帝国》的屏幕后面,利用自己的技术实力积极入侵网络。然而,许多攻击的现实情况远比这平凡得多。
一封带有“未送达”等无害主题的简单电子邮件被放在员工的垃圾邮件文件夹中。他们心…

Windows配置域名映射IP
一、找到 hosts 文件
打开 C:\Windows\System32\drivers\etc
二、添加hosts文件修改、写入权限 右击hosts文件,点击属性 -> 安全 -> Users -> 编辑 -> Users -> 添加修改、写入权限 -> 确定 -> 确定 进入常规,将只读属性关闭 三、…

浅尝一下Godot Shader
前言 这几天下来总算是整理到Shader了,先说结论,Godot的Shader非常非常好用。理由:
1.集成好;2.易编写;3.见效快(均是相对于Unity)。
基础探索 一定要夸的是,Godot引擎真的非常轻便…

详细描述一下Elasticsearch索引文档的过程?
大家好,我是锋哥。今天分享关于【详细描述一下Elasticsearch索引文档的过程?】面试题。希望对大家有帮助; 详细描述一下Elasticsearch索引文档的过程?
Elasticsearch的索引文档过程是其核心功能之一,涉及将数据存储到…

K8S资源限制之LimitRange
LimitRange介绍
LimitRange也是一种资源,在名称空间内有效;限制同一个名称空间下pod容器的申请资源的最大值,最小值pod的resources中requests和limits必须在这个范围内,否则pod无法创建。当然pod也可以不使用resources进行创建ty…

运算放大器的学习(三)增益带宽积
我们接着了解运放的相关指标参数,下面我们看下增益带宽积与压摆率. 增益带宽积:即电压增益(Gain)和带宽(Bandwidth)的乘积是一个常数,称为增益带宽积(Gain Bandwidth Product). 增益…

编译报错:protoc did not exit cleanly. Review output for more information.
目录标题 解决“protoc did not exit cleanly”的报错问题检查.proto文件的语法 解决“protoc did not exit cleanly”的报错问题
今天做的项目需要用到grpc,然后需要编写proto然后编译后实现grpc的具体方法! 结果编译的时候报了protoc did not exit cl…